Hi,
Another update:
So our software wraps around AliceO2::roc library to do direct register accesses to the CRU and the HDLC core.
As an example, I did a read of the GPIO DIN register of the SCA, i.e. SCA command GPIO_R_DATAIN, which consists of four register accesses indicated in bold:
HdlcCernMe::sendFrame_(HdlcEcFramePayload& r) const
{
uint32_t wdata, wcmd;
assembleRegisters(r, wcmd, wdata);
bar_.write(base_addr_ + REG_WR_DATA, wdata);
bar_.write(base_addr_ + REG_WR_CMD, wcmd);
startFrameTx();
}
uint32_t
HdlcCernMe::getFrame(HdlcEcFramePayload& r) const
{
disassembleRegisters(r, bar_.read(base_addr_ + REG_RD_CMD), bar_.read(base_addr_ + REG_RD_DATA));
return r.error;
}
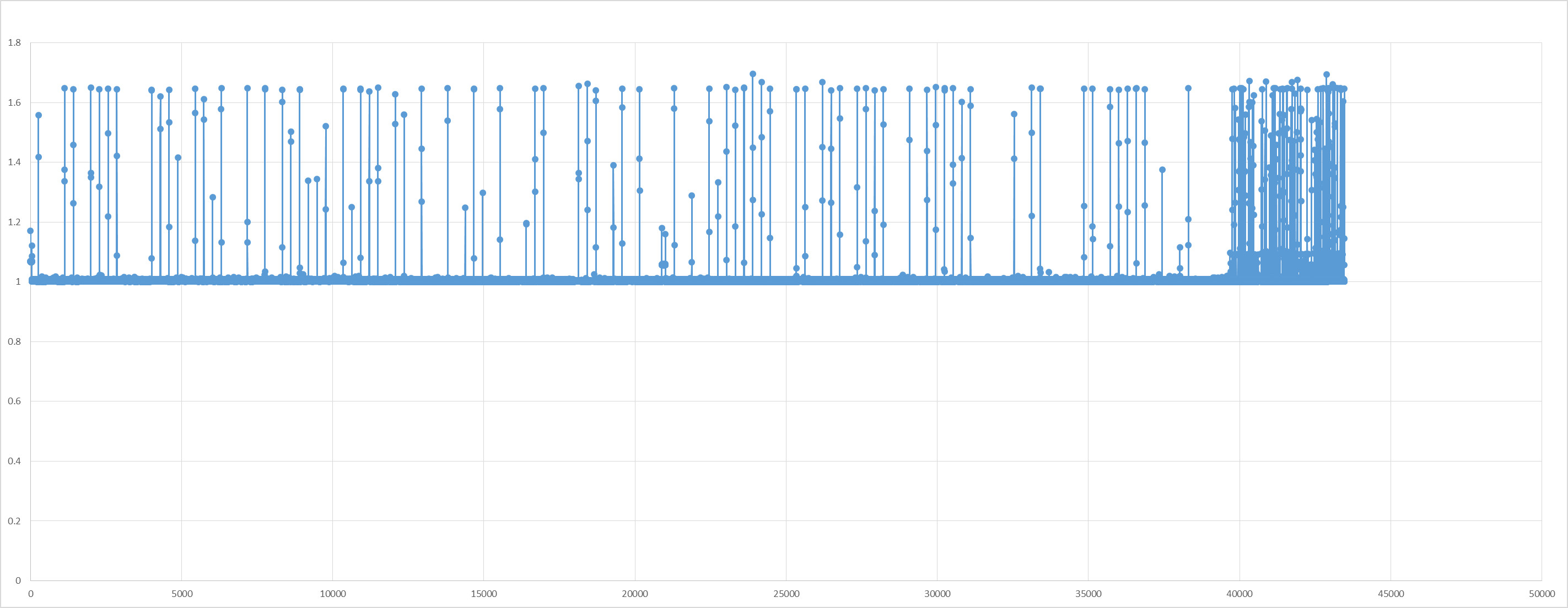
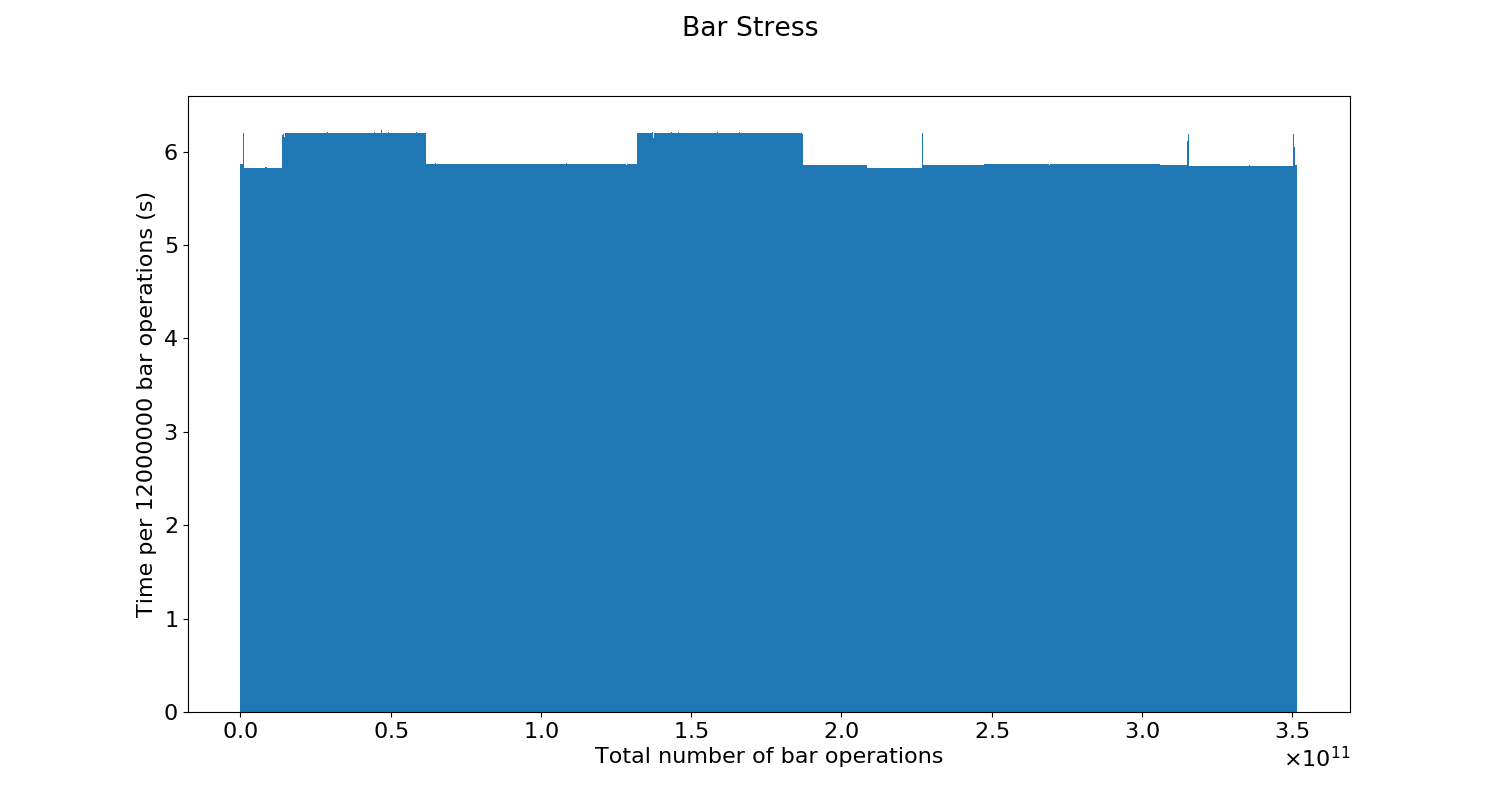
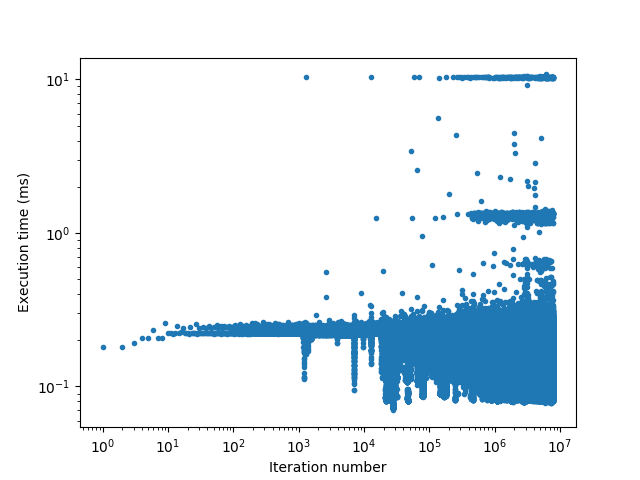
Now, after the system starts to be slow, we see these four accesses takes around 125 ms each.
-bash-4.2$ perf trace --duration 10.0 tsca --id 04:00.0 -m 0x4 --gpio-din
42.812 (127.143 ms): tsca/41016 write(fd: 3</sys/bus/pci/drivers/uio_pci_dma/new_id>, buf: 0x7f120a3d3000, count: 9) = 9
189.331 (125.418 ms): tsca/41016 write(fd: 3</sys/bus/pci/drivers/uio_pci_dma/new_id>, buf: 0x7f120a3d3000, count: 9) = 9
379.624 (125.411 ms): tsca/41016 write(fd: 3</sys/bus/pci/drivers/uio_pci_dma/new_id>, buf: 0x7f120a3d3000, count: 9) = 9
524.309 (126.205 ms): tsca/41016 write(fd: 3</sys/bus/pci/drivers/uio_pci_dma/new_id>, buf: 0x7f120a3d3000, count: 9) = 9
[gpio-din] 0x20a02540
I then reinitialized the DMA driver, and it drops very substantially to ~0.3 ms:
-bash-4.2$ (perf trace tsca --id 04:00.0 -m 0x4 --gpio-din) > test.log 2>&1
-bash-4.2$ cat test.log | grep write
44.745 ( 0.377 ms): tsca/20326 write(fd: 3, buf: 0x7f24122c6000, count: 9 ) = 9
66.412 ( 0.278 ms): tsca/20326 write(fd: 3, buf: 0x7f24122c6000, count: 9 ) = 9
133.096 ( 0.283 ms): tsca/20326 write(fd: 3, buf: 0x7f24122c6000, count: 9 ) = 9
154.833 ( 0.284 ms): tsca/20326 write(fd: 3, buf: 0x7f24122c6000, count: 9 ) = 9